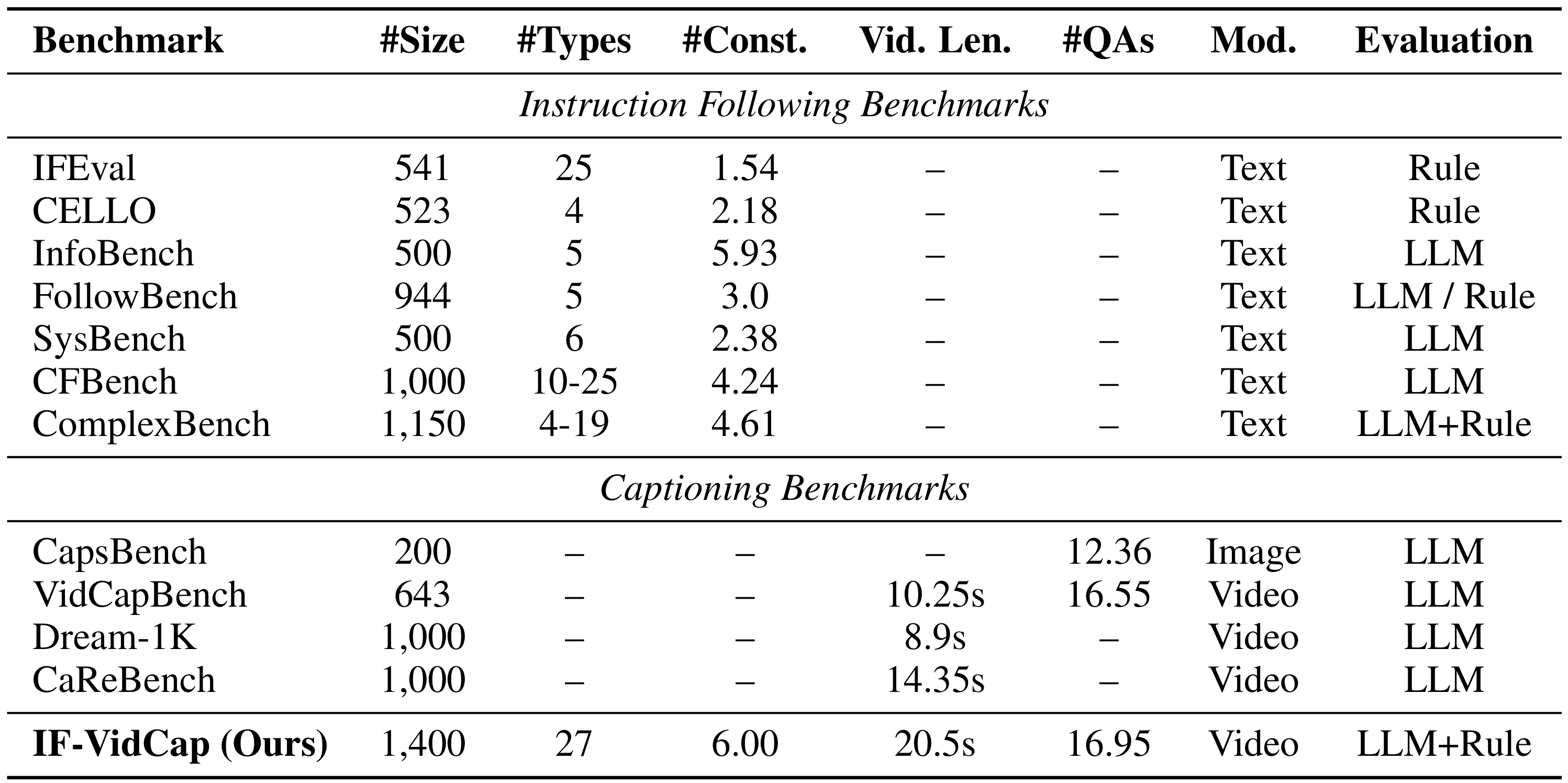
ISR: Instruction Satisfaction Rate CSR: Content Satisfaction Rate
Rule-Based ISR/CSR: Only considers format-related constraints. Open-ended ISR/CSR: Only considers content-related constraints.
By default, this leaderboard is sorted by overall ISR, with CSR as a secondary sort key. To view other sorted results, please click on the corresponding cell.
The “Frame” column represents the frame rate (float) or fixed frame number(integer).
| # | Model | LLM Params |
Frames | Date | Overall (%) | Rule-Based (%) | Open-ended (%) | |||
|---|---|---|---|---|---|---|---|---|---|---|
| ISR | CSR | ISR | CSR | ISR | CSR | |||||
| - | Gemini-2.5-pro | - | - | - | 27.83 | 74.53 | 74.35 | 87.81 | 35.22 | 59.00 |
| - | Qwen3-VL-235B-A22B-Instruct | 235 | 2 | - | 26.41 | 71.65 | 67.16 | 84.14 | 36.39 | 57.12 |
| - | Gemini-2.5-flash | - | - | - | 25.50 | 72.63 | 67.80 | 84.51 | 35.45 | 58.71 |
| - | InternVL3.5-241B-A28B_thinking | 241B | 1.0 | - | 24.20 | 71.17 | 65.58 | 83.21 | 34.64 | 57.13 |
| - | GPT-4o | - | - | - | 22.90 | 70.74 | 69.20 | 85.12 | 30.94 | 53.91 |
| - | InternVL3.5-38B_thinking | 38B | 1.0 | - | 20.71 | 68.30 | 59.43 | 80.17 | 31.79 | 54.42 |
| - | Gemini-2.0-flash | - | - | - | 18.19 | 67.45 | 63.04 | 82.06 | 26.86 | 50.39 |
| - | Qwen2.5-VL-72B-Instruct | 72B | 2.0 | - | 17.50 | 67.28 | 64.29 | 83.22 | 25.71 | 48.65 |
| - | InternVL3.5-8B_thinking | 8B | 1.0 | - | 17.33 | 65.90 | 60.32 | 79.95 | 26.84 | 49.50 |
| - | InternVL3.5-38B_nothinking | 38B | 1.0 | - | 15.43 | 64.76 | 57.79 | 78.92 | 24.93 | 48.20 |
| - | Qwen2.5-VL-32B-Instruct | 32B | 2.0 | - | 15.16 | 64.04 | 53.66 | 76.95 | 26.72 | 48.94 |
| - | VideoLLaMA3-7B_thinking | 7B | 2.0 | - | 12.21 | 57.38 | 48.64 | 71.69 | 19.93 | 40.65 |
| - | Qwen2.5-VL-7B-Instruct | 7B | 2.0 | - | 1.92 | 58.12 | 52.51 | 73.81 | 18.75 | 39.65 |
| - | MiniCPM-V-4.5_thinking | 8B | 2.0 | - | 11.75 | 61.67 | 58.09 | 79.35 | 18.05 | 40.97 |
| - | VideoLLaMA3-7B_nothinking | 7B | 2.0 | - | 10.63 | 57.17 | 47.34 | 71.21 | 18.46 | 40.75 |
| - | InternVL3.5-8B_nothinking | 8B | 1.0 | - | 9.96 | 56.45 | 48.14 | 71.68 | 16.98 | 38.65 |
| - | MiniCPM-V-4.5_nothinking | 8B | 2.0 | - | 8.57 | 59.23 | 56.07 | 77.62 | 14.64 | 37.73 |
| - | Qwen2.5-VL-3B-Instruct | 3B | 2.0 | - | 6.54 | 51.74 | 43.46 | 66.50 | 13.15 | 34.47 |
| - | Llama-3.2-90B-Vision-Instruct | 90B | 1.0 | - | 5.80 | 45.18 | 36.03 | 59.56 | 11.03 | 28.36 |
| - | Llama-3.2-11B-Vision-Instruct | 11B | 1.0 | - | 4.00 | 39.87 | 31.29 | 53.24 | 7.71 | 24.25 |
| - | llava-v1.6-vicuna-7b | 7B | 32 | - | 3.54 | 43.92 | 35.84 | 60.09 | 7.30 | 25.02 |
| - | Video-LLaVA | 7B | 8 | - | 3.13 | 38.74 | 26.53 | 51.27 | 7.73 | 24.05 |
| - | ARC-Hunyuan-Video-7B | 7B | 1.0 | - | 2.32 | 27.78 | 12.23 | 31.41 | 9.11 | 23.54 |
| - | Tarsier2-7B | 7B | 1.0 | - | 1.40 | 26.05 | 9.30 | 27.75 | 9.91 | 24.04 |
| - | IF-Captioner-Qwen(Ours) | 7B | 2.0 | - | 12.76 | 61.64 | 58.50 | 78.81 | 19.65 | 41.56 |
Date: indicates the publication date of open-source models -: indicates "unknown" for closed-source models